Lesson: Working with Text
Section: Detecting Text Boundaries
Java 教程是为 JDK 8 编写的。本页中描述的示例和实践未利用在后续版本中引入的改进。
字符边界
如果应用程序允许终端用户高亮单个字符或一次将文本移动一个字符,则需要定位字符边界。要创建定位字符边界的 BreakIterator,请调用 getCharacterInstance 方法,如下所示:
BreakIterator characterIterator =
BreakIterator.getCharacterInstance(currentLocale);
这种类型的 BreakIterator 检测用户字符之间的边界,而不仅仅是 Unicode 字符。
用户字符可以由多个 Unicode 字符组成。例如,用户字符 ü 可以通过组合 Unicode 字符 \u0075 (u)和 \u00a8(¨) 来组成。但是,这不是最好的示例,因为字符 ü 也可以由单个 Unicode 字符 \u00fc 表示。我们将借鉴阿拉伯语,以获得更真实的例子。
在阿拉伯语中,house 这个词是:
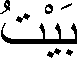
该单词包含三个用户字符,但它由以下六个 Unicode 字符组成:
String house = "\u0628" + "\u064e" + "\u064a" + "\u0652" + "\u067a" + "\u064f";
house 字符串中位置 1,3 和 5 处的 Unicode 字符是变音符号。阿拉伯语需要变音符号,因为它们可以改变单词的含义。示例中的变音符号是非间距字符,因为它们出现在基本字符上方。在阿拉伯文字处理器中,你无法为字符串中的每个 Unicode 字符移动光标一次。相反,你必须为每个用户字符移动一次,这可能由多个 Unicode 字符组成。因此,你必须使用 BreakIterator 来扫描字符串中的用户字符。
示例程序 BreakIteratorDemo,创建 BreakIterator 以扫描阿拉伯字符。程序将此 BreakIterator 以及之前创建的 String 对象传递给名为 listPositions 的方法:
BreakIterator arCharIterator = BreakIterator.getCharacterInstance(
new Locale ("ar","SA"));
listPositions (house, arCharIterator);
listPositions 方法使用 BreakIterator 来定位字符串中的字符边界。请注意,BreakIteratorDemo 使用 setText 方法将特定字符串分配给 BreakIterator。程序使用 first 方法获取第一个字符边界,然后调用 next 方法,直到返回常量 BreakIterator.DONE。此例程的代码如下:
static void listPositions(String target, BreakIterator iterator) {
iterator.setText(target);
int boundary = iterator.first();
while (boundary != BreakIterator.DONE) {
System.out.println (boundary);
boundary = iterator.next();
}
}
listPositions 方法为字符串 house 中的用户字符打印出以下边界位置。请注意,变音符号(1,3,5)的位置未列出:
0 2 4 6